
Phonotactics in historical linguistics
Published:
My PhD thesis, with the catchy title Phonotactics in historical linguistics: Quantitative interrogation of a novel data source is now available (open access) on UQ eSpace.
I thought I’d have a go at writing about what I’ve been up to for the last five years. The aim here is to explain in plain English what my research is about and the point of it all. My target audience, in part, is friends and family who are curious about what I’ve been doing but don’t necessarily have a linguistic background. Readers with linguistic expertise will have to be patient while I explain some concepts and terminology. You’ll also have to forgive me if I over-simplify things or gloss over important points. Of course, you’re welcome to check out the thesis itself for more detailed explanations in technical language ;-)
One of my favourite areas of research is linguistic phylogenetics, i.e. investigating how languages are historically related and how human language evolves through time, using phylogenetic methods. In my PhD, I tested the question of whether language phylogenies could be inferred with greater confidence by using phonotactic data in combination with cognate data. Unfortunately, there are multiple technical words in that sentence and even for a trained linguist a natural reaction would be something like a confused “what!? why??”. So, in this post, I’ll go over some of the background and motivations driving this question. I’ll follow it up later with a Part II post discussing the research papers that made up the bulk of my thesis and all my findings.
Language trees
Languages share historical relationships. Many folks will be familiar with the idea of different modern languages sharing a common ancestor language, for example, modern Romance languages (Italian, Spanish, French, etc.) descending from Latin. Another example is the Germanic subgroup that English belongs to. Some people mistakenly believe that English itself is a Romance language, due to the large amount of vocabulary that has been borrowed into English from Norman French. English and French do, however, share a relationship if you go back further in time — both the Romance and Germanic language subgroups are related to each other within the larger Indo-European family, a huge language family spanning from Iceland to India.
There are kinds of historical relatedness other than descent from a common ancestor, for example, borrowing between languages in contact (e.g. English and Norman French, as mentioned above) and the formation of pidgins and creoles. Nevertheless, one of the main ways of representing these kinds of relationships is via family trees. Again, this concept might already be familiar to many — maybe you’ve seen this attractive illustration of Indo-European that’s been doing the rounds on the internet for a while.
One of the key jobs of the historical linguist is to infer family trees of languages, more technically known as phylogenies. Of course, there’s no way to go back in time and directly observe when and how languages split from their ancestor tongue. We have to piece back together these trees as best we can from the evidence at hand. European languages have been studied extensively for the last 200 years or so and their family tree, or phylogeny, is fairly well understood. But there are plenty of parts of the world where the picture is far more sketchy, particularly for understudied families of indigenous languages in Australia, New Guinea, North and South America, and so there’s a lot more work to be done.
How to infer a language phylogeny
Traditionally, one of the main sources of evidence are cognates — sets of words in different languages that share a common source. For example, check out the table below. These resemblances aren’t coincidental. All these words share in origin the proto-Indo-European word *pH₂tér- (meaning father).
| Sanskrit | Latin | Ancient Greek | Italian | English | German |
|---|---|---|---|---|---|
| pitṛ́ | pater | pater | padre | father | Vater |
(German Vater is pronounced with an f at the start)
It turns out that the differences between these words are not coincidental either. If you assemble a large collection of cognate sets, you can start to observe systematic patterns, or sound correspondences. What’s more, with some crafty detective work, plus some knowledge of speech physiology and how speech sound systems tend to operate, it is possible to piece together some of the historical sound changes that a language has undergone. Some of the first people to study this stuff systematically were the Grimm brothers (yes, the fairytale ones) who identified what’s now known as Grimm’s law. For example, the correspondence between proto-Indo-European /p/ in words like father (which survives in, e.g., the Romance languages and Greek today) and Germanic /f/ reappears in other examples, like the words for ‘foot’ (proto-IE: *pōds, Italian: piede, German: Fuß).
This is obviously a small, limited example, and I’m glossing over some detail. As you can imagine, assembling cognates and identifying sound changes from systematic sound correspondences quickly becomes a complex, tricky task when you add more languages and lexicon. Hopefully this illustrates the general process though. Historical linguists assemble cognates, they identify correspondences between sounds that recur systematically across different cognate sets, from this they identify historical sound change processes, and from this they can group languages into subgroups and families. And this is one of the primary ways of inferring family trees of languages.
Without downplaying all the interesting developments in the field of historical linguistics in the last 200 years, it is genuinely remarkable how consistent this basic methodology has remained since the brothers Grimm. However, there has been one major development over the last 20 years. This is the rise in computational phylogenetic methods for inferring trees of languages.
How to infer a language phylogeny with computers!
Computational phylogenetic methods have largely been developed in biology for inferring phylogenies of species. As an aside, the histories of evolutionary biology and linguistics are kind of interesting. The earliest ‘tree’ diagrams of languages actually predate Darwin’s tree diagrams of species slightly (pictured below). Darwin himself dabbled with the idea of language evolution in his writings. The fields share somewhat of an intertwined past there in the beginning, before diverging for much of the last century, before coming together again to some degree in the first two decades of this century.
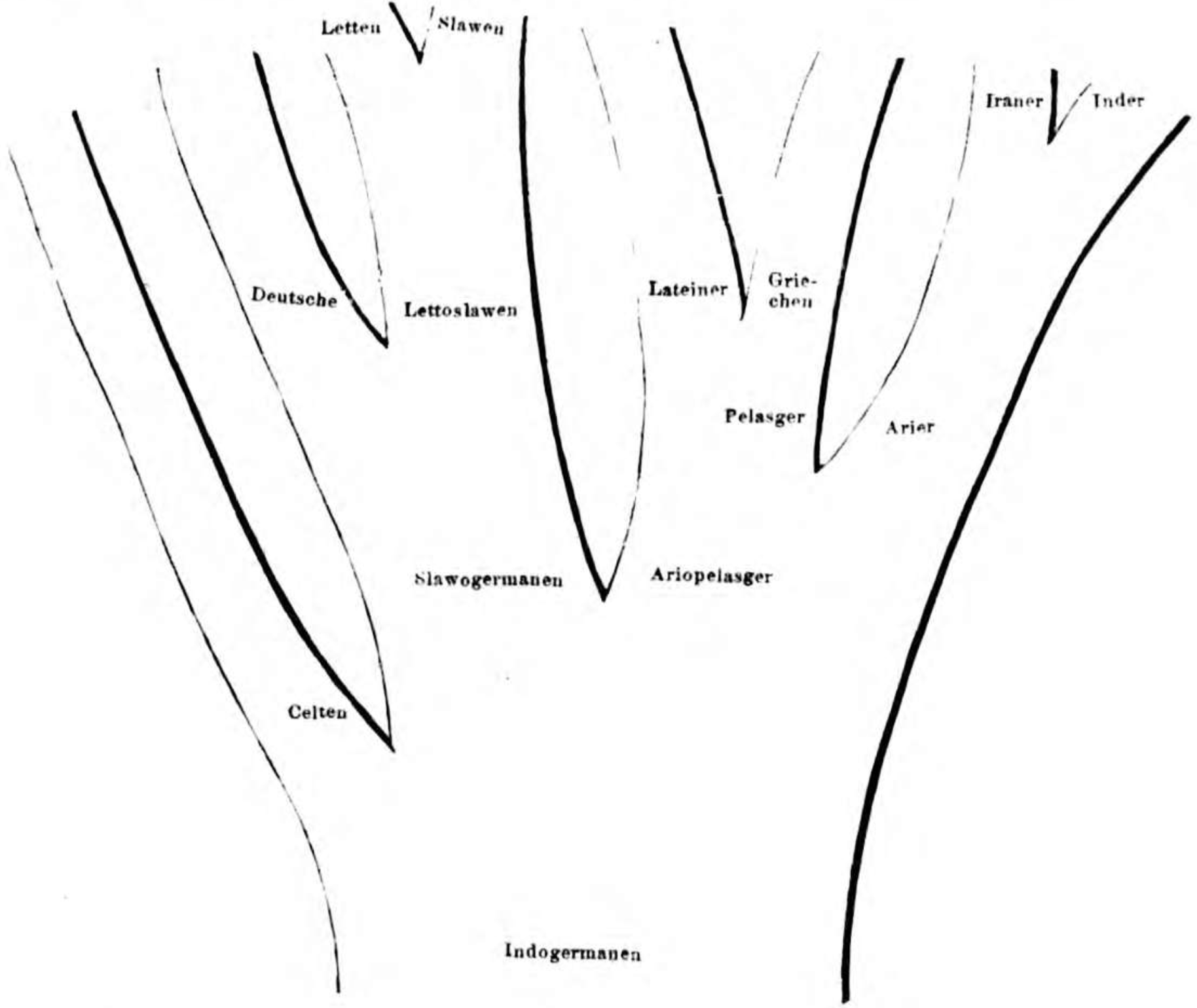
Figure 1. August Schleicher’s “stammbaum” diagram of languages, published in 1853 (predating Darwin’s On the origin of Species by 6 years).
So anyway, back to these computational phylogenetic methods. You need data, you need an evolutionary model (a mathematical framework describing how the data evolves), and you need a computer that can crunch the numbers and give you a tree (or perhaps a whole forest of trees). For data, biologists have been able to benefit from huge strides in genetics and genomic sequencing in recent decades. Genetic data has largely replaced [morphological data](https://en.wikipedia.org/wiki/Morphology_(biology%29) for inferring phylogenetic trees of species. In linguistics, the question of what to use for data is a little more open-ended. By far the most common strategy is to use lexical cognate data. This involves binarising the kinds of congnate sets we encountered in the previous section. A language gets a ‘1’ if it includes a word in a particular cognate set or a ‘0’ if it does not. For example, if we jump back to the table of words for ‘father’ above, each of those languages, Sanskrit, Latin, Ancient Greek, Italian, English and German, would all be coded with a ‘1’ which signifies that they all contain a cognate word related to that proto-Indo-European word *pH₂tér-. Other languages that use unrelated words for father, for example Nepalese (बुबा, Bubā = father), would be coded with a ‘0’. Go through and code all cognate sets for 100–200 basic meaning categories and you get a very large table of 1s and 0s for each language of study.
Bayesian computational methods are the state of the art for turning these spreadsheets of binary cognate data into phylogenetic trees. This allows you to specify prior knowledge in the evolutionary model. For example, you might have archaeological evidence tying a language to a particular time and place. You can include this information to constrain the kinds of trees the software will produce accordingly. There are a whole bunch of details in the evolutionary model that can be played with, governing things like evolutionary rates (how frequently 1s and 0s can change through time), whether and how these rates can vary in different parts of the tree, the relative likelihood of a 0 turning to a 1 versus a 1 turning to a 0 and so forth. Once the model is set up nicely, it’s time to hit the big red button and let the computer run a Markov Chain Monte Carlo process (MCMC). The reason for this is that there are practically infinite ways that a set of languages bigger than a small handful can be linked in a phylogenetic tree. It would be impossible to test every single possible tree. The MCMC process is a genius method for searching just a small subset of all the possibilities in a principled way, honing in on a high-likelihood solution.
MCMC works like so. The computer produces a family tree linking all the languages at random — besides adhering to any tree constraints you might have specified previously, it’ll literally just produce a big random set of bifurcating branches linking everything up. Then it calculates how likely this tree would be given the evolutionary model and the language data. As you can imagine, this random tree is almost certainly nonsense and thus the likelihood score will be low. Next, it produces another random tree and calculates a new likelihood score for the new tree. If the likelihood score is better (or even just very slightly below*) the previous likelihood score, the new tree ‘wins’ that round and the previous tree is discarded. If not, the new tree is discarded and the previous tree is retained. Then the computer produces another random tree and repeats the process. And then it repeats it again. And again. Millions and millions of times. In a pinch, you might be able to get away with 10 million iterations, but for anything publication quality you’re really looking at 100 million or more. Obviously, the first many iterations are junk, but the truly remarkable thing is how quickly and efficiently this MCMC process searches the probability space, narrows in and stabilises around the best solution.
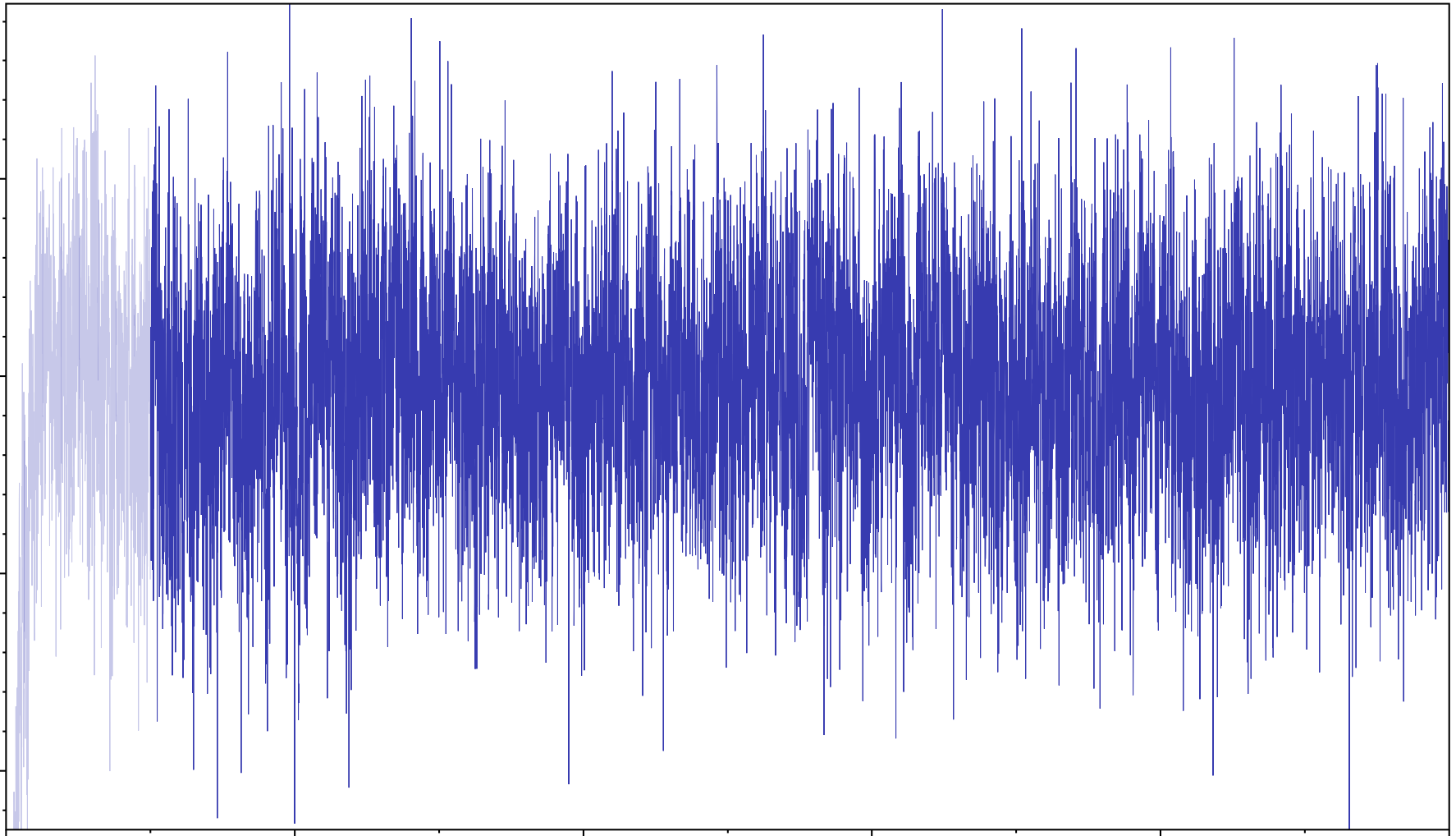
Figure 2. A relatively well behaved MCMC chain. This kind of trace diagram shows the likelihood score for each iteration from the first iteration on the left to the 100 millionth iteration on the right. You can see it starts off pretty wild in the burn-in period, which is why we discard the first 10% (greyed out on the left) but quickly stabilises.
At the end, you’re left not with one single best tree but a whole forest of millions of trees, one from each MCMC iteration. Typically, you discard the first 10% or so as ‘burn-in’ (when the computer is just starting out exploring the probability space and starts off with junky trees before finding better solutions), then you take every 1000th tree (or 2000th or 10,000th tree or so, whatever works) so you end up with a final sample of at least a thousand, perhaps several thousand, high quality, high likelihood trees to work with.
Why not simply take the very last tree, the final ‘winner’ with the highest likelihood of all? Well, the issue is that although, yes, the final tree will have a good likelihood score, the second last tree will also have a very high likelihood score, only very slightly less than the final tree. And so who’s to say that the second last, or the third last tree (and so on) aren’t actually more accurate than the final one? By working with a whole sample, or forest, of trees, which are all quite similar and all quite high likelihood, we get an indication of phylogenetic uncertainty. We’re accepting the fact that we don’t know the one true, historical tree — these are just our best estimates, and the best representation of the real, true tree probably lies somewhere in that forest but we can’t be sure exactly where. If we want a nice family tree figure for the family of languages, there are ways of averaging this forest into a kind of single best average tree like this one, complete with confidence levels indicated on each node, which is really nice.
*Why ever accept a tree with a slighly lower probability than the tree before? Just to add a degree of flexibility. Otherwise the MCMC process tends to get stuck on a particular peak in the probability space and start going around in circles. You’ve got to allow it to accept slighly lower probability trees occasionally so it can go down again and properly explore the probability space around it. Otherwise if it gets stuck on the first peak, it might never find the even bigger peak that lies just over a valley below.
The limits of cognate data
Over the last 20 years or so, linguists have had a tremendous degree of success inferring language phylogenies using cognate data using the methods described above. You can now find phylogenies for major language families in most parts of the world, including the Indo-European (multiple times), Pama-Nyungan, Austronesian, Bantu, Sino-Tibetan families, and more.
Nevertheless, there are some limitations. Perhaps the biggest one is just how difficult and time consuming cognate data is to acquire. Coding enormous tables of thousands of cognates is hard work. It’s also a job that requires a good deal of familiarity with the languages at hand, in order to discern which words are likely related to others (and, for example, which words look somewhat similar but are more likely to be chance resemblances or borrowings).
One of the results is that, although language phylogenies have been inferred for a good assortment of major language families around the world, there are buckets more language families for which this work remains undone. For example, we have some nice phylogenies of the Pama-Nyungan family, the biggest language family in Australia, but not for the plethora of smaller families packed into the Top End and Kimberley regions. New Guinea, arguably the most linguistically diverse place on earth, remains practically untouched by phylogenetic methods.
Phonotactics
All human languages have rules about how sounds are allowed to fit into syllables and words. Languages will forbid certain sounds from ever appearing together in sequence. This system of rules is called phonotactics. Phonotactics is language specific; some languages are highly restrictive about what they allow and others are perfectly happy with long, complex consonant clusters. For example, consider the sequence ‘sf’. English never allows words to start with ‘sf’, it just doesn’t work. Italian is perfectly happy to let words start with ‘sf’ though (e.g. sforzo, effort). Likewise, Italian words can start with ‘sb’ (e.g. sbaglio, mistake) which isn’t allowed in English.
One of the things that makes phonotactics interesting from a historical perspective is that phonotactic restrictions tend to be quite resilient. A language’s lexicon, from which we get cognate data, is changing all the time as speakers of the language invent new words, borrow words from neighbouring languages, and send old words out of fashion. Borrowings can be particularly problematic for phylogenetic methods, because they can get erroneously marked as cognates (as if two languages both inherited the word from a common ancestor rather than one language borrowing the word from the other).
Phonotactics, by contrast, is a bit more historically conservative. That’s not to say phonotactic rules never change — they can and do change sometimes. But we can observe languages preserving phonotactic restrictions even as they borrow vocabulary from other languages. Some of my favourite examples illustrating this come from the word ‘Christmas’ rendered into different languages. Japanese, which is incredibly restrictive about consonant clusters and never allows words to end with a vowel, turns ‘Christmas’ into kurisumasu, with a heap of vowels inserted to break those consonant clusters up. As Bing Crosby teaches us, ‘Merry Christmas’ in Hawaiian is meli kalikimaka, which is the result of applying both Hawaiian’s strict (C)V(V) syllable structure (C = consonant, V = vowel, brackets = optional) and famously constrained phoneme inventory (in which English’s ‘l’ and ‘r’ sounds both belong to the same sound category, and there is no ‘s’ sound). So we see that even though these languages both borrowed the word ‘Christmas’, they adapted it to fit existing phonotactic restrictions.
One of the other interesting things about phonotactics is that you can extract a lot about a language’s phonotactics straight from a wordlist, and you can even automate large parts of the process. You can tell a lot about which sequences of sounds are allowed to go together and which sequences never go together just by seeing which sequences appear in the language’s wordlist and which don’t. This means you can get a large volume of data fairly quickly using computers, without the need to make complex cognate judgements, and you can do so even for languages that are understudied and under-resourced, just as long as you’ve got a decent list of words.
My research question
So, at last, we get to the overarching research question driving my PhD. I wanted to know whether I could combine existing cognate data with new phonotactic data to infer phylogenetic trees of languages, using the Pama-Nyungan family as a test case. Testing this is simple enough in essence: Infer a tree using cognates, infer a tree using cognates and phonotactic data, and see which one “wins”. Of course, testing this question was quite a bit more complex in practice, but that’s the idea.
To be clear, the goal is not to create a silver bullet method for automatically inferring trees just from simple wordlists. Cognate data is, and will remain, tremendously valuable. If inferring trees with phonotactics worked, it would mean we’d have an extra nifty source of data to complement cognates and other lines of evidence.
Because this post has already become quite lengthy, I’ll leave it here on a cliffhanger. In a Part II follow-up, I’ll discuss the papers I wrote as part of my thesis, what I found, the difficulties I faced and what it all means. Thanks for sticking around!